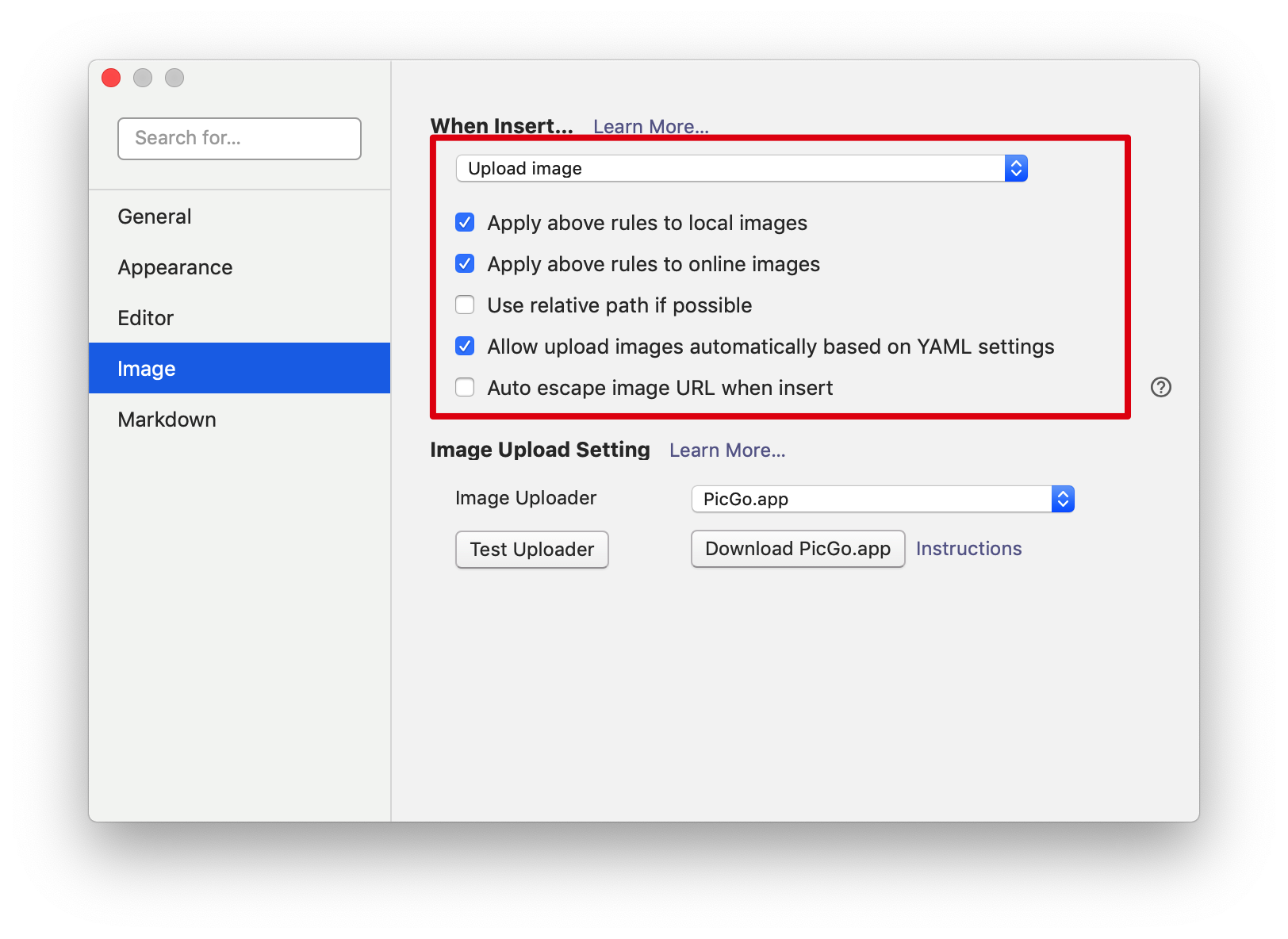
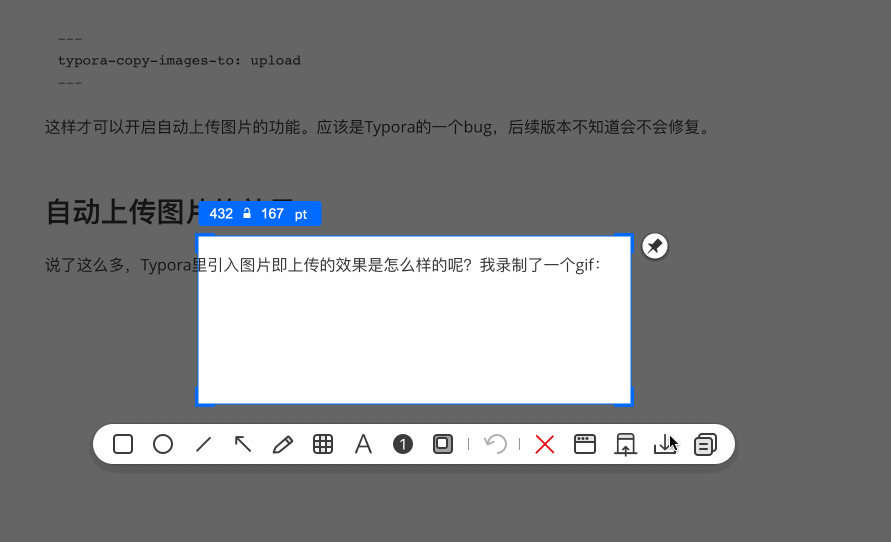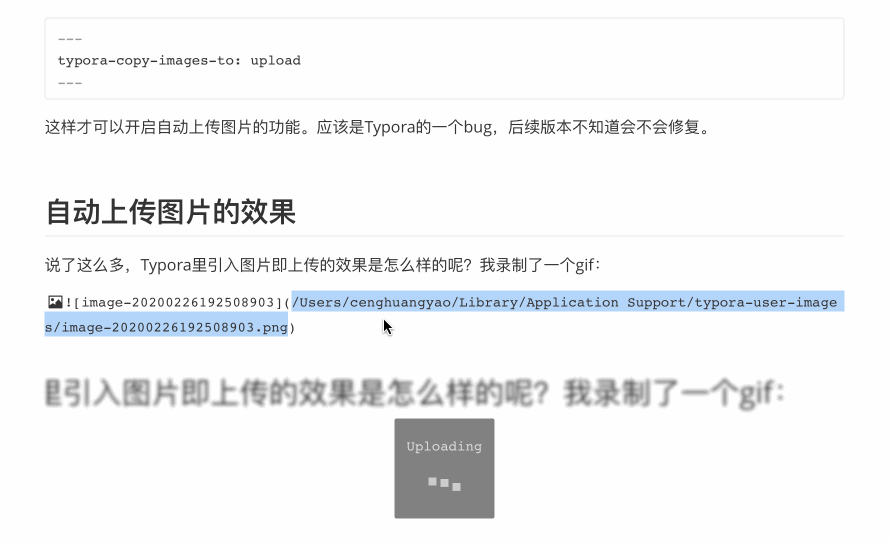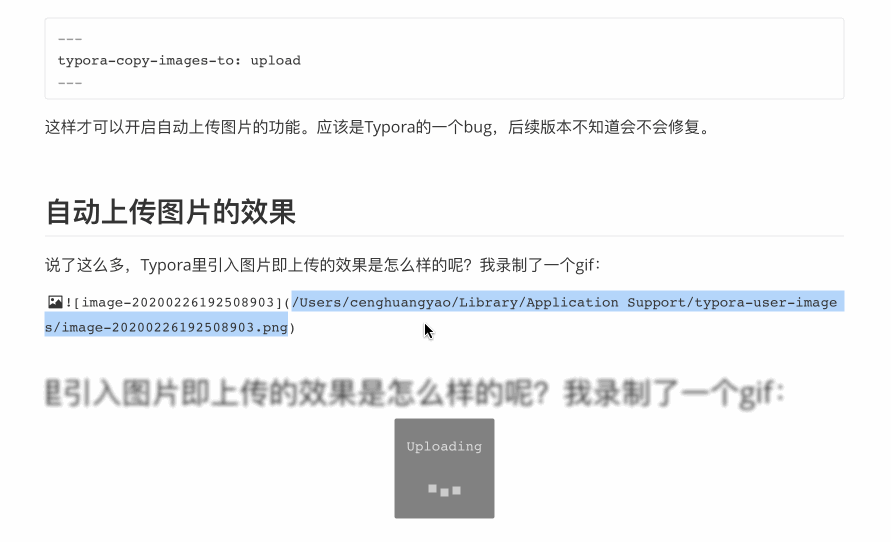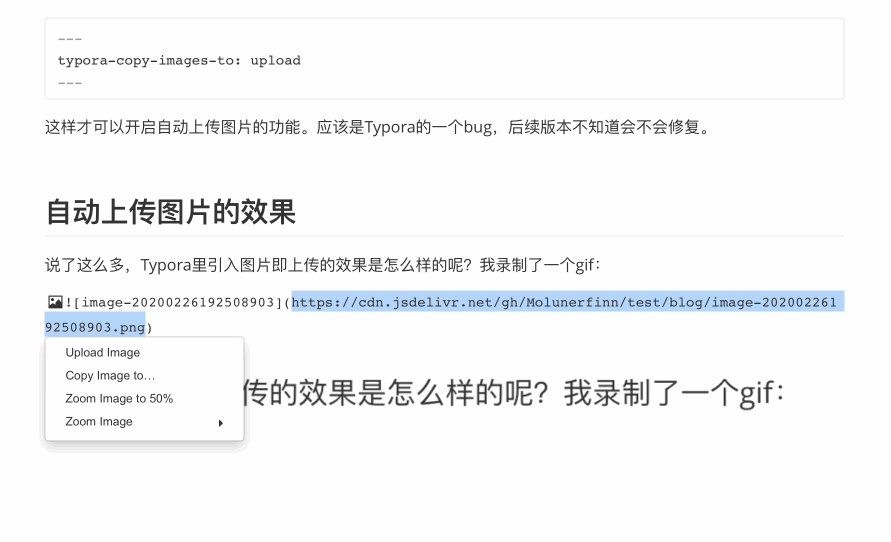
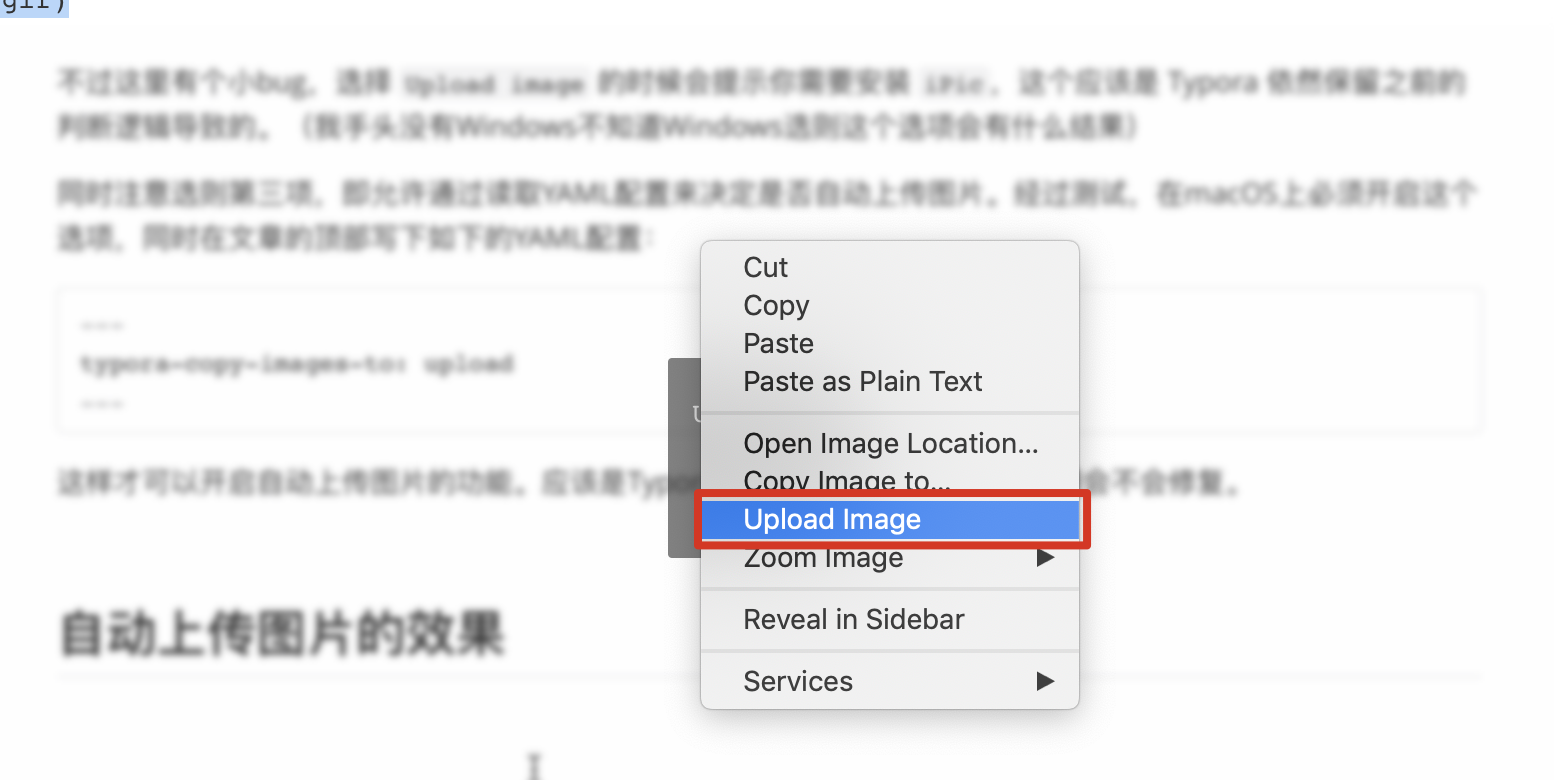
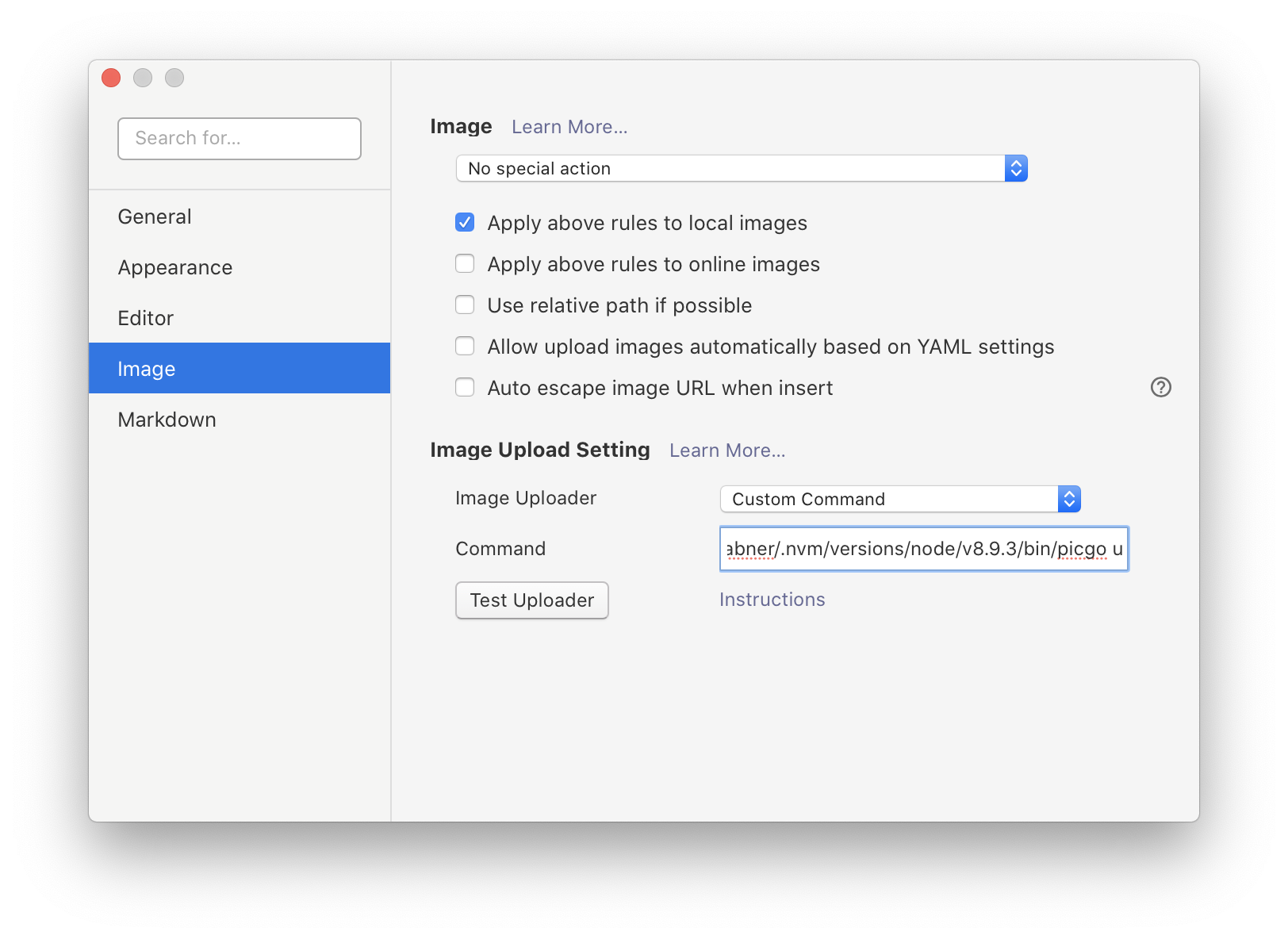
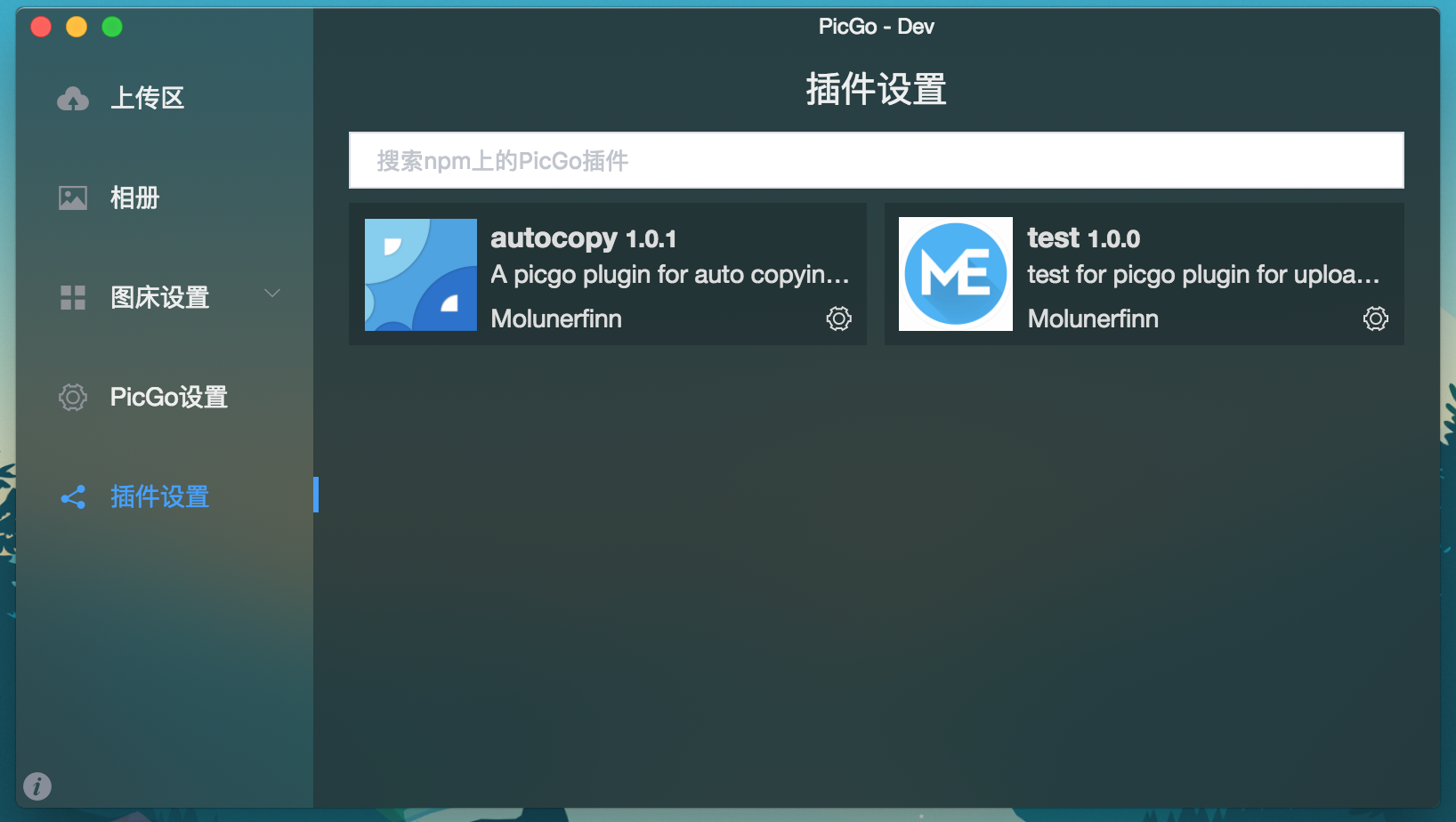
前言祝大家2019年猪年新年快乐!本文较长,需要一定耐心看完哦~
前段时间,我用electron-vue 开发了一款跨平台(目前支持主流三大桌面操作系统)的免费开源的图床上传应用——PicGo ,在开发过程中踩了不少的坑,不仅来自应用的业务逻辑本身,也来自electron本身。在开发这个应用过程中,我学了不少的东西。因为我也是从0开始学习electron,所以很多经历应该也能给初学、想学electron开发的同学们一些启发和指示。故而写一份Electron的开发实战经历,用最贴近实际工程项目开发的角度来阐述。希望能帮助到大家。
预计将会从几篇系列文章 或方面来展开:
electron-vue入门 Main进程和Renderer进程的简单开发 引入基于Lodash的JSON database——lowdb 跨平台的一些兼容措施 通过CI发布以及更新的方式 开发插件系统——CLI部分 开发插件系统——GUI部分 想到再写… 说明 PicGo是采用electron-vue开发的,所以如果你会vue,那么跟着一起来学习将会比较快。如果你的技术栈是其他的诸如react、angular,那么纯按照本教程虽然在render端(可以理解为页面)的构建可能学习到的东西不多,不过在main端(electron的主进程)应该还是能学习到相应的知识的。
如果之前的文章没阅读的朋友可以先从之前的文章 跟着看。
说在前面,其实这篇文章写起来真的很难。如何构建一个插件系统,我花了半年的时间。要在一篇或者两篇文章里把这个东西说好是真的不容易。所以可能行文上会有一些瑕疵,后续会不断打磨。
插件系统——容器 相信很多人平时更多的是给其他框架诸如Vue、React或者Webpack等写插件。我们可以把提供插件系统的框架称为「容器」,通过容器暴露出来的API,插件可以挂载到容器上,或者接入容器的生命周期来实现一些更定制化的功能。
比如Webpack本质上是一个流程系统,它通过Tapable 暴露了很多生命周期的钩子,插件可以通过接入这些生命周期钩子实现流水线作业——比如babel系列的插件把ES6代码转义成ES5;SASS、LESS、Stylus系列的插件把预处理的CSS代码编译成浏览器可识别的正常CSS代码等等。
我们要实现一个插件系统,本质上也是实现这么一个容器。这个容器以及对应的插件需要具备如下基本特征:
容器在没有 第三方插件 接入的情况下也能 实现基本功能 插件具有独立性 插件可配置可管理 第一点应该很容易理解。如果一个插件系统因为没有第三方插件的存在就无法运行,那么这个插件系统有什么用呢?不过有别于第三方插件,很多插件系统有自己内置的插件,比如vue-cli、Webpack的一系列内置插件。这个时候插件系统本身的一些功能就会由内置的插件去实现。
第二点,插件的独立性是指插件本身运行时不会 主动 影响其他插件的运作。当然某个插件可以依赖于其他插件的运行结果。
第三点,插件如果不能配置不能管理,那么从安装插件阶段就会遇到问题。所以容器需要有设计良好的入口给予插件注册。
接下来的部分,我将结合PicGo-Core 与PicGo 来详细说明CLI插件系统与GUI插件系统如何构建与实现。
CLI插件系统 概述 其实CLI插件系统可以认为是无GUI的插件系统,也就是运行在命令行或者不带有可视化界面的插件系统。为什么我们开发Electron的插件系统,需要扯到CLI插件系统呢?这里需要简单回顾一下Electron的结构:
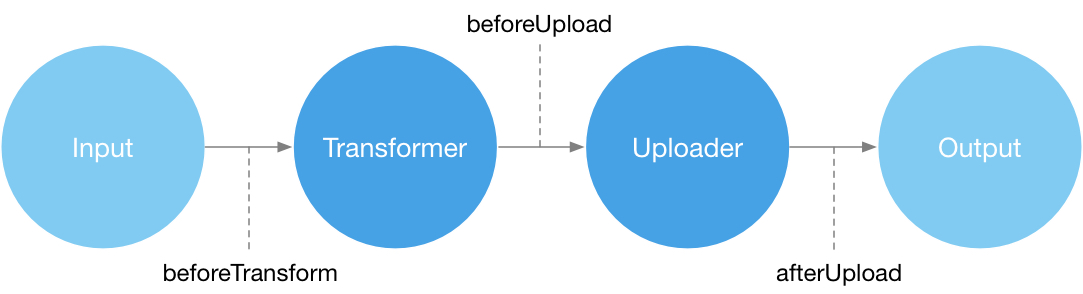
可以看到除了Renderer的界面渲染,大部分的功能是由Main进程提供的。对于PicGo而言,它的底层应该是一个上传流程系统,如下:
Input(输入):接受来自外部的输入,默认是通过路径或者完整的图片base64信息 Transformer(转换器):把输入转换成可以被上传器上传的对象(包含图片尺寸、base64、图片名等信息) Uploader(上传器):将来自转换器的输出上传到指定的地方,默认的上传器将会是SM.MS Output(输出):输出上传的结果,通常可以在输出的imgUrl里拿到结果 所以理论上它的底层应该在Node.js端就能实现。而Electron的Renderer进程只是实现了GUI界面,去调用底层Node.js端实现的流程系统提供的API而已。类似于我们平时在开发网页时候的前后端分离,只不过现在这个后端是基于Node.js实现的插件系统。基于这个思路,我开始着手PicGo-Core 的实现。
生命周期 通常来说一个插件系统都有自己的一个生命周期,比如Vue有beforeCreate、created、mounted等等,Webpack有beforeRun、run、afterCompile等等。这个也是一个插件系统的灵魂所在,通过接入系统的生命周期,赋予了插件更多的自由度。
因此我们可以先来实现一个生命周期类。代码可以参考Lifecycle.ts 。
生命周期流程可以参考上面的流程图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Lifecycle { async start (input: any []): Promise <void > { try { await this .beforeTransform(input) await this .doTransform(input) await this .beforeUpload(input) await this .doUpload(input) await this .afterUpload(input) } catch (e) { console .log(e) } } private async beforeTransform (input) { } private async doTransform (input) { } private async beforeUpload (input) { } private async doUpload (input) { } private async afterUpload (input) { } }
在实际使用中,我们可以通过:
1 2 const lifeCycle = new LifeCycle()lifeCycle.start([...])
来运行整个上传流程的生命周期。不过到这里我们还没有看到任何跟插件相关的东西。这是为了实现我们说的第一个条件: 容器在没有 第三方插件 接入的情况下也能 实现基本功能 。
广播事件 很多时候我们需要将一些事件以某种方式传递出去。就像发布订阅模型一样,由容器发布,由插件订阅。这个时候我们可以直接让Lifecycle这个类继承Node.js自带的EventEmmit:
1 2 3 4 5 6 class Lifecycle extends EventEmitter { constructor ( super () } }
那么Lifecycle也就拥有了EventEmitter的emit和on方法了。对于容器来说,我们只需要emit事件出去即可。
比如在PicGo-Core里,上传的整个流程都会往外广播事件,通知插件当前进行到什么阶段,并且将当前的输入或者输出在广播的时候发送出去。
1 2 3 4 private async beforeTransform (input) { this .emit('beforeTransform' , input) }
插件可以自由选择监听想要监听的事件。比如插件想要知道上传结束后的结果(伪代码):
1 2 3 plugin.on('finished' , (output ) => { console .log(output) })
在开发PicGo-Core的时候,有一些很有用的事件。在这里我也想分享出来,虽然不是所有插件系统都会有这样的事件,但是结合自己和项目的实际需要,他们有的时候很有用。
进度事件 平时我们上传或者下载文件的时候,都会注意一个东西:进度条。同样,在PicGo-Core里也暴露了一个事件,叫做uploadProgress,用于告诉用户当前的上传进度。不过在PicGo-Core,上传进度是从beforeTransform就开始算了,为了方便计算,划分了5个固定的值。
1 2 3 4 5 6 7 8 9 10 11 12 private async beforeTransform (input) { this .emit('uploadProgress' , 0 ) } private async doTransform (input) { this .emit('uploadProgress' , 30 ) } private async beforeUpload (input) { this .emit('uploadProgress' , 60 ) } private async afterUpload (input) { this .emit('uploadProgress' , 100 ) }
如果上传失败的话就返回-1:
1 2 3 4 5 6 7 8 9 10 11 12 async start (input: any []): Promise <void > { try { await this .beforeTransform(input) await this .doTransform(input) await this .beforeUpload(input) await this .doUpload(input) await this .afterUpload(input) } catch (e) { console .log(e) this .emit('uploadProgress' , -1 ) } }
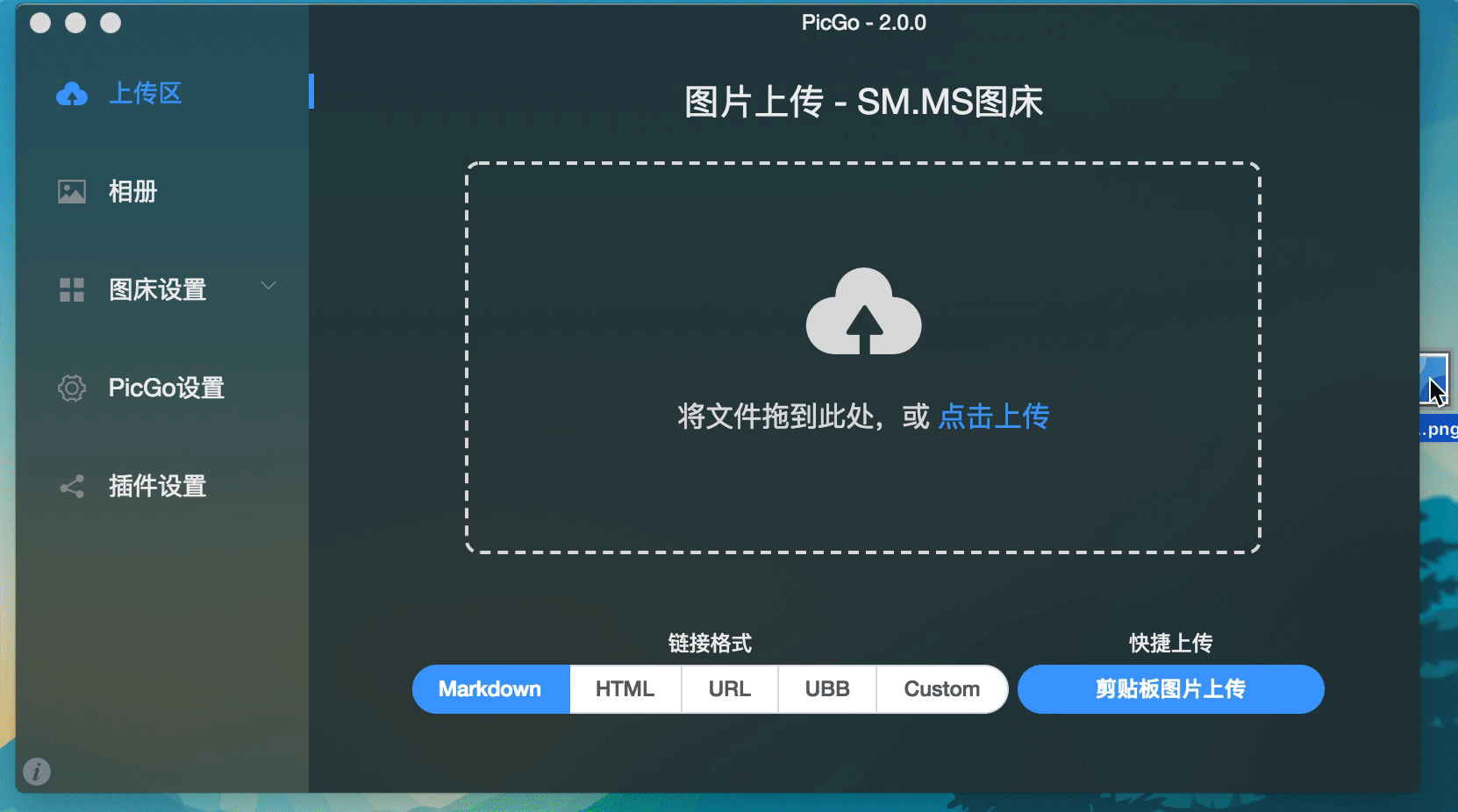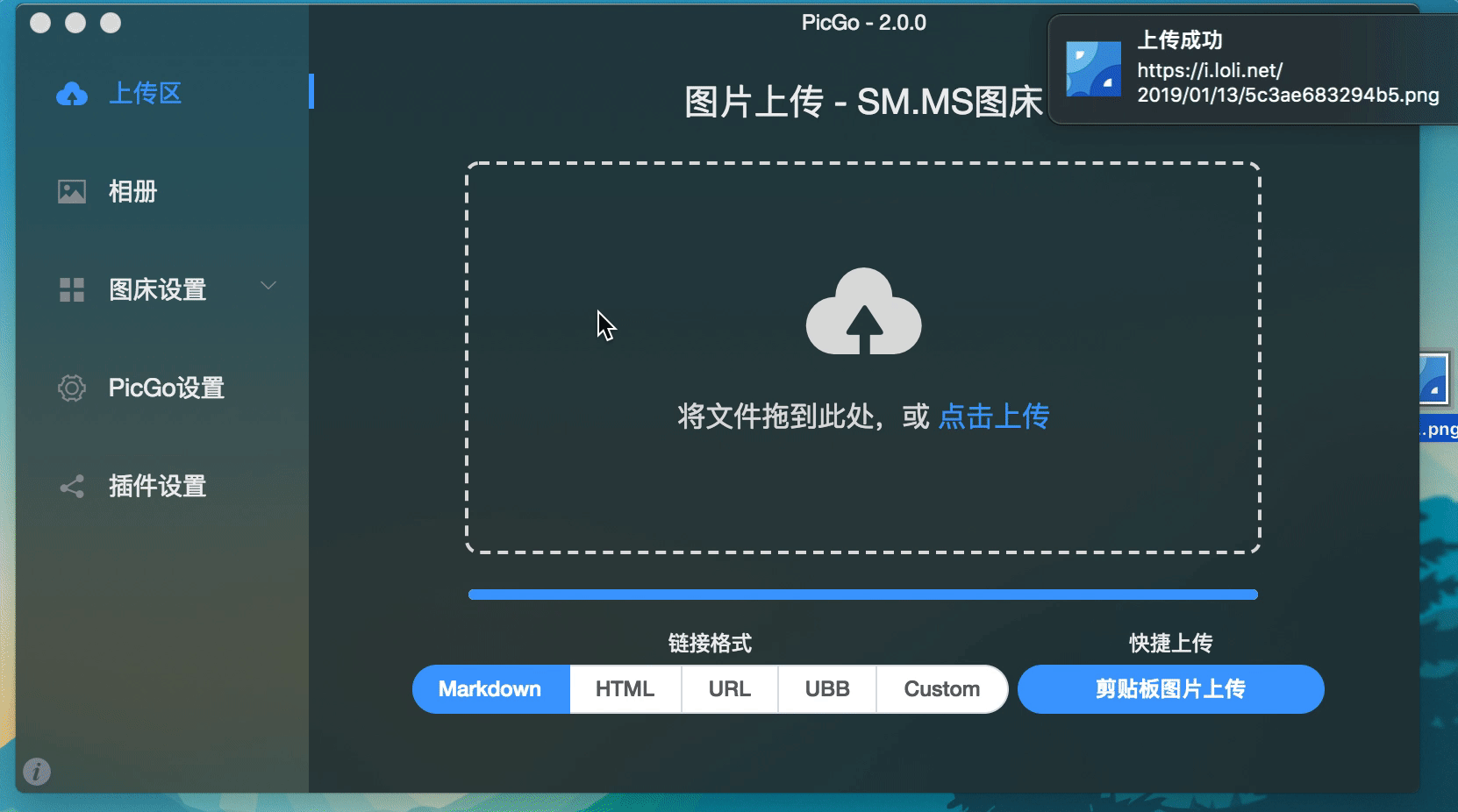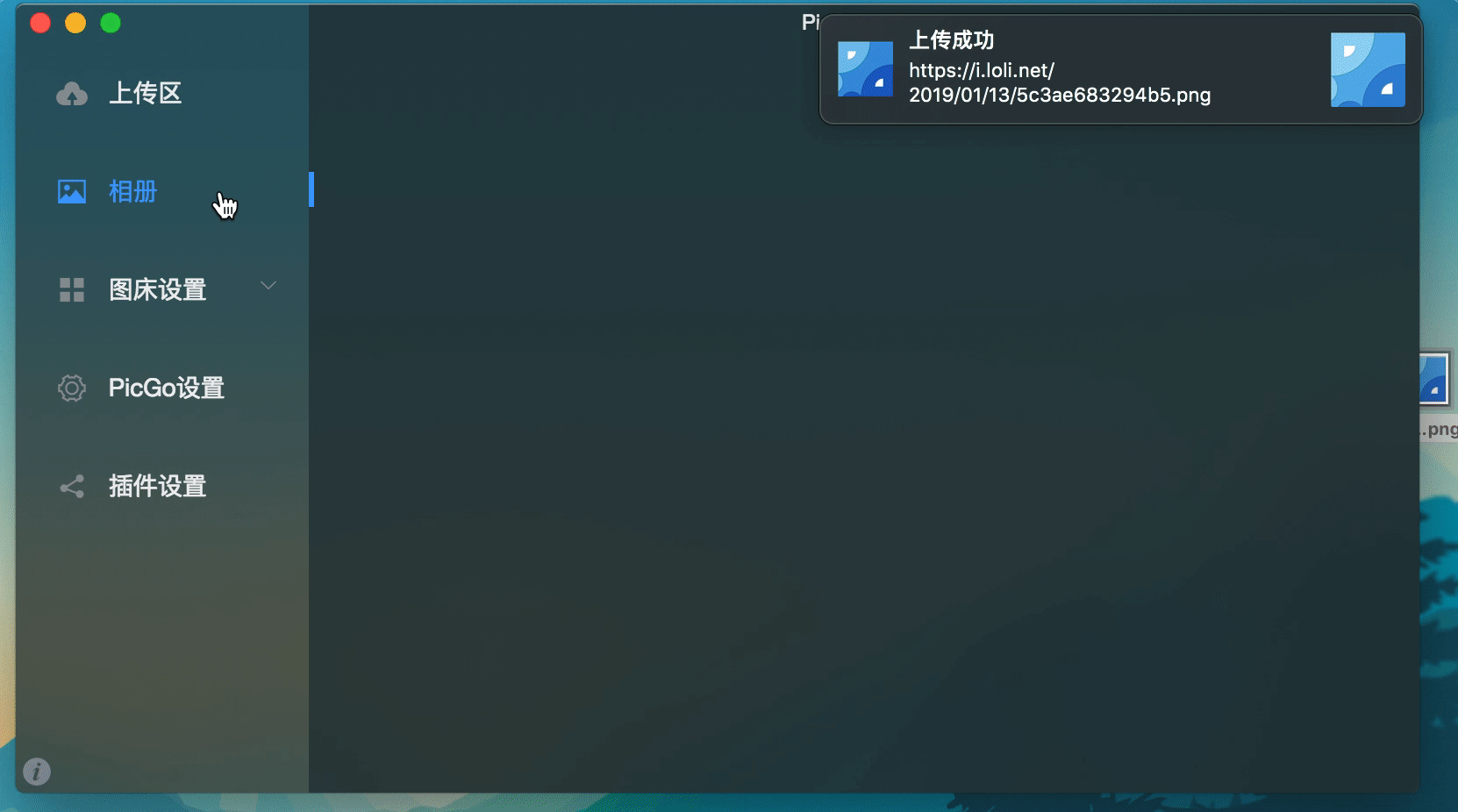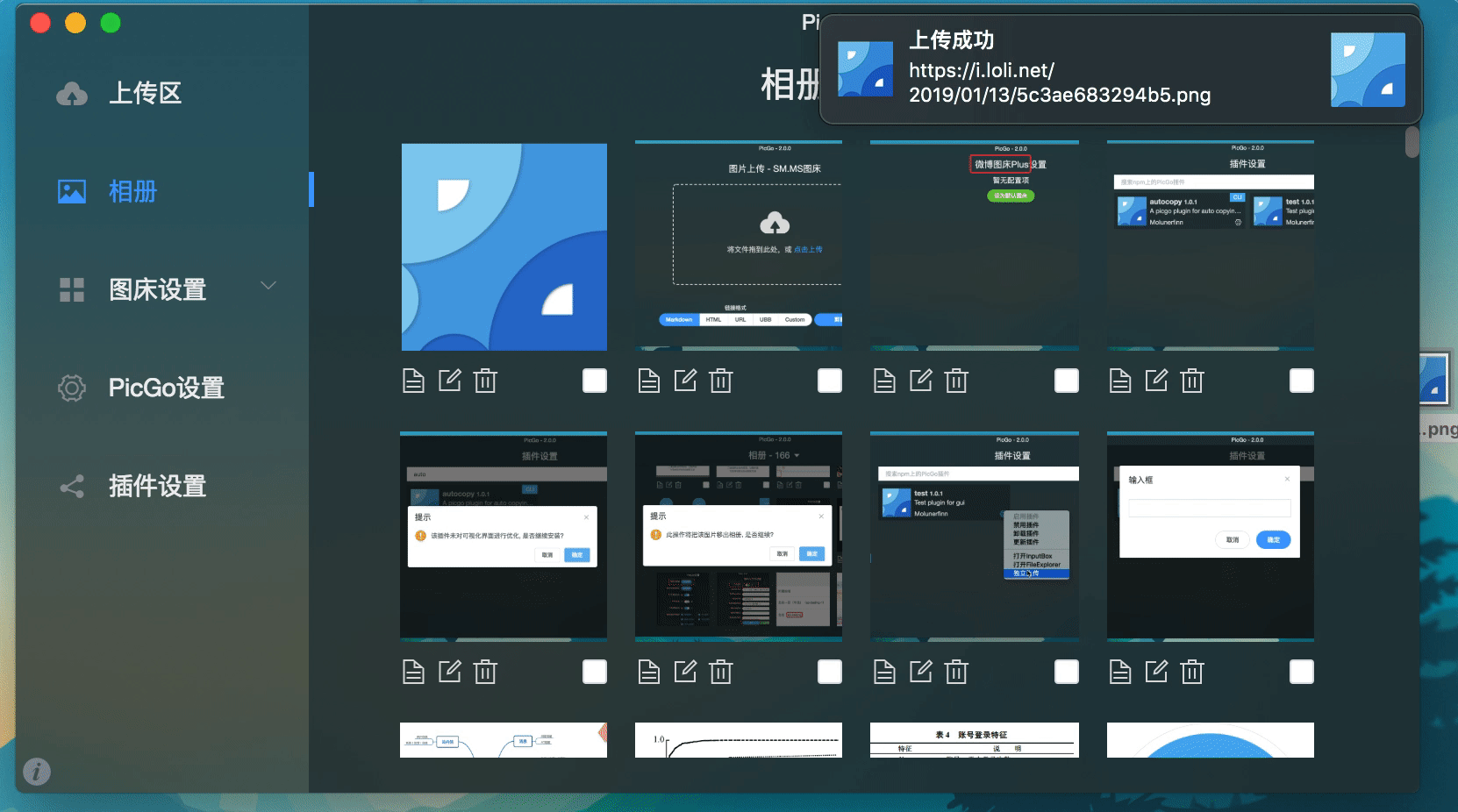
通过监听这个事件,PicGo就能做出如下的上传进度条:
系统通知 如果上传出了问题,或者有些信息需要通过系统级别的通知告诉用户的话,可以发布notification事件。通过监听这个事件可以调用系统通知来发布。插件也可以发布这个事件,让PicGo监听。如上图上传成功后右上角的通知。
接入生命周期 上部分讲到了生命周期中的事件广播,可以发现事件广播是只管发不管结果的。也就是PicGo-Core只管发布这个事件,至于有没有插件监听,监听后做了什么都不用关心。(怎么有点像UDP一样)。但是实际上很多时候我们需要接入生命周期做一些事情的。
就拿上传流程来说,我要是想要上传前压缩图片,那么监听beforeUpload事件是做不到的。因为在beforeUpload事件里就算你把图片已经压缩了,恐怕上传的流程早就走完了,emit事件出去后生命周期照旧运行。
因此我们需要在容器的生命周期里实现一个功能,能够让插件接入它的生命周期,在执行完当前生命周期的插件的动作后,才把结果送往下一个生命周期。可以发现,这里有一个「等待」插件执行的动作。因此PicGo-Core使用最简易而直观的async函数配合await来实现「等待」。
我们先不用考虑插件是如何注册的,后文会说到。我们先来实现怎么让插件接入生命周期。
下面以生命周期beforeUpload为例:
1 2 3 4 5 6 private async beforeUpload (input) { this .ctx.emit('uploadProgress' , 60 ) this .ctx.emit('beforeUpload' , input) await this .handlePlugins(beforeUploadPlugins.getList(), input) }
可以看到我们通过await等待生命周期方法handlePlugins(下文会说明如何实现)的执行结束。而我们运行的插件列表是通过beforeUploadPlugins.getList()(下文会说明如何实现)获取的,说明这些是只针对beforeUpload这个生命周期的插件。然后将输入input传入handlePlugins让插件们调用即可。
现在我们实现一下handlePlugins:
1 2 3 4 5 private async handlePlugins (plugins: Plugin[], input: any []) { await Promise .all(plugins.map(async (plugin: Plugin) => { await plugin.handle(input) })) }
我们通过Promise.all以及await来「等待」所有插件执行。这里需要注意的是,每个PicGo插件需要实现一个handle方法来供PicGo-Core调用。可以看到,这里实现我们说的第二个特征: 插件具有独立性 。
从这里也能看到我们通过async和await构建了一个能够「等待」插件执行结束的环境。这样就解决了光是通过广播事件无法接入插件系统的生命周期的问题。
不,等等,这里还有一个问题。beforeUploadPlugins.getList()是哪来的?上面只是一个示例代码。实际上PicGo-Core根据上传流程里的不同生命周期预留了五种不同的插件:
beforeTransformPlugins transformer beforeUploadPlugins uploader afterUploadPlugins 分别在上传的5个周期里调用。虽然这5种插件调用的时机不一样,但是它们的实现是同样的:有同样的注册机制、同样的方法用于获取插件列表、获取插件信息等等。所以我们接下去来实现一个生命周期的插件类。
生命周期插件类 这个是插件系统里很关键的一环,这个类的实现了插件应该以什么方式注册到我们的插件系统里,以及插件系统如何获取他们。这块的代码可以参考 LifecyclePlugins.ts 。
以下是实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class LifecyclePlugins { list: { [propName: string ]: Plugin } constructor ( this .list = {} } register (id: string , plugin: Plugin): void { if (!id) throw new TypeError ('id is required!' ) if (typeof plugin.handle !== 'function' ) throw new TypeError ('plugin.handle must be a function!' ) if (this .list[id]) throw new TypeError (`${this .name} duplicate id: ${id} !` ) this .list[id] = plugin } get (id: string ): Plugin { return this .list[id] } getList (): Plugin[] { return Object .keys(this .list).map((item: string ) => this .list[item]) } getIdList (): string [] { return Object .keys(this .list) } } export default LifecyclePlugins
对于插件而言最重要的是register方法,它是插件注册的入口。通过register注册后,会在Lifecycle内部的list以id:plugin形式里写入这个插件。注意到,PicGo-Core要求每个插件需要实现一个handle的方法,用于之后在生命周期里调用。
这里用伪代码说明一下插件要如何注册:
1 2 3 4 5 beforeTransformPlugins.register('test' , { handle (ctx) { console .log(ctx) } })
这里我们就注册了一个id叫做test的插件,它是一个beforeTransform阶段的插件,它的作用就是打印传入的信息。
然后在不同的生命周期里,调用LifeCyclePlugins.getList()的方法就能获取这个生命周期对应的插件的列表了。
抽离出核心类 如果仅仅是实现一个能够在Node.js项目里运行的插件系统,上面两个部分基本就够了:
Lifecyle类负责整个生命周期 LifecylePlugins类负责插件的注册与调用 不过一个良好的CLI插件系统还需要至少如下的部分(至少我觉得):
可以通过命令行调用 能够读取配置文件进行额外配置 命令行一键安装插件 命令行完成插件配置 友好的log信息提示 此处可以参考vue-cli3这个工具。
因此我们至少还需要如下的部分:
命令行操作相关的类 配置文件操作相关 插件安装、卸载、更新等相关操作的类 插件加载相关的类 日志信息输出相关的类 这上面的几个部分都跟生命周期类本身没有特别强的耦合关系,所以可以不必将它们都放到生命周期类里实现。
相对的,我们抽离出一个Core作为核心,将上述这些类包含到这个核心类中,核心类负责命令行命令的注册、插件的加载、优化日志信息以及调用生命周期等等。
最后再将这个核心类暴露出去,供使用者或者开发者使用。这个就是PicGo-Core的核心 PicGo.ts 的实现。
PicGo本身的实现并不复杂,基本上只是调用上述几个类实例的方法。
不过注意到这里有一个之前一直没有提到的东西。PicGo-Core除了核心PicGo之外的几个子类里,基本上在constructor构建函数阶段都会传入一个叫做ctx的参数。这个参数是什么?这个参数是PicGo这个类自身的this。通过传入this,PicGo-Core的子类也能使用PicGo核心类暴露出来的方法了。
比如Logger类实现了美观的命令行日志输出:
那么在其他子类里想要调用Logger的方法也很容易:
1 ctx.log.success('Hello world!' )
其中ctx就是我们上面说的,PicGo自身的this指针。
我们接下去介绍的每个类具体的实现。
日志输出相关类 先从这个类开始说起是因为这个类是最简单而且侵入性最小的一个类。有它没它都行,但是有它自然是锦上添花。
PicGo实现美化日志输出的库是chalk ,它的作用就是用来输出花花绿绿的命令行文字:
用起来也很简单:
1 2 const log = chalk.green('Success' )console .log(log)
我们打算实现4种输出类型,success、warn、info和error:
于是创建如下的类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import chalk from 'chalk' import PicGo from '../core/PicGo' class Logger { level: { [propName: string ]: string } ctx: PicGo constructor (ctx: PicGo ) { this .level = { success: 'green' , info: 'blue' , warn: 'yellow' , error: 'red' } this .ctx = ctx } protected handleLog (type : string , msg: string | Error ): string | Error | undefined { if (!this .ctx.config.silent) { let log = chalk[this .level[type ]](`[PicGo ${type .toUpperCase()} ]: ` ) log += msg console .log(log) return msg } else { return } } success (msg: string | Error ): string | Error | undefined { return this .handleLog('success' , msg) } info (msg: string | Error ): string | Error | undefined { return this .handleLog('info' , msg) } error (msg: string | Error ): string | Error | undefined { return this .handleLog('error' , msg) } warn (msg: string | Error ): string | Error | undefined { return this .handleLog('warn' , msg) } } export default Logger
之后再将Logger这个类挂载到PicGo核心类上:
1 2 3 4 5 6 7 8 9 import Logger from '../lib/Logger' class PicGo { log: Logger constructor ( this .log = new Logger(this ) } }
这样其他挂载到PicGo核心类上的类就能使用ctx.log来调用log里的方法了。
配置文件相关 很多时候我们的所写的系统也好、插件也好,或多或少需要一些配置之后才能更好地使用。比如vue-cli3的vue.config.js,比如hexo的_config.yml等等。而PicGo也不例外。默认情况下它可以直接使用,但是如果想要做些其他操作,自然就需要配置了。所以配置文件是插件系统很重要的一个组成部分。
之前我在Electron版的PicGo上使用了lowdb 作为JSON配置文件的读写库,体验不错。为了向前兼容PicGo的配置,写PicGo-Core的时候我依然采用了这个库。关于lowdb的一些具体用法,我在之前的一篇文章里有提及,有兴趣的可以看看——传送门 。
由于lowdb做的是类似MySQL一样的持久化配置,它需要磁盘上一个具体的JSON文件作为载体,所以无法通过创建一个配置对象去初始化配置。因此一切都从这个配置文件展开:
PicGo-Core采用一个默认的配置文件:homedir()/.picgo/config.json,如果在实例化PicGo没提供配置文件路径那么就会使用这个文件。如果使用者提供了具体的配置文件,那么就会使用所提供的配置文件。
下面来实现一下PicGo初始化的过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import fs from 'fs-extra' class PicGo extends EventEmitter { configPath: string private lifecycle: Lifecycle constructor (configPath: string = '' ) { super () this .configPath = configPath this .init() } init () { if (this .configPath === '' ) { this .configPath = homedir() + '/.picgo/config.json' } if (path.extname(this .configPath).toUpperCase() !== '.JSON' ) { this .configPath = '' return this .log.error('The configuration file only supports JSON format.' ) } const exist = fs.pathExistsSync(this .configPath) if (!exist) { fs.ensureFileSync(`${this .configPath} ` ) } } }
那么在实例化PicGo的时候就是如下这样:
1 2 3 4 5 6 const PicGo = require ('picgo' )const picgo = new PicGo() const picgo = new PicGo('./xxx.json' )
有了配置文件之后,我们只需要实现三个基本操作:
初始化配置 读取配置 写入配置(写入配置包括创建、更新、删除等) 初始化配置 一般来说我们的系统都会有一些默认的配置,PicGo也不例外。我们可以选择把默认配置写到代码里,也可以选择把默认配置写到代码里。因为PicGo的配置文件有持久化的需求,所以把一些关键的默认配置写入配置文件是合理的。
初始化配置的时候会用到lowdb 的一些知识,这里就不展开了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import lowdb from 'lowdb' import FileSync from 'lowdb/adapters/FileSync' const initConfig = (configPath: string ): lowdb.LowdbSync<any > => { const adapter = new FileSync(configPath, { deserialize: (data: string ): Function => return (new Function (`return ${data} ` ))() } }) const db = lowdb(adapter) if (!db.has('picBed' ).value()) { db.set('picBed' , { current: 'smms' }).write() } if (!db.has('picgoPlugins' ).value()) { db.set('picgoPlugins' , {}).write() } return db }
那么在PicGo初始化阶段就可以将configPath传入,来实现配置的初始化,以及获取配置。
1 2 3 4 5 init () { let db = initConfig(this .configPath) this .config = db.read().value() }
读取配置 一旦初始化配置之后,要获取配置就很容易了:
1 2 3 4 5 6 7 8 import { get } from 'lodash' getConfig (name: string = '' ): any { if (name) { return get (this .config, name) } else { return this .config } }
这里用到了lodash的get方法,主要是为了方便获取如下情况:
比如配置内容长这样:
1 2 3 4 5 { "a" : { "b" : true } }
往常我们要获取a.b需要:
万一遇到a不存在的时候,那么上面那句话就会报错了。因为a不存在,那么a.b就是undefined.b自然会报错了。而用lodash的get方法则可以避免这个问题,并且可以很方便的获取:
1 let b = get (this .config, 'a.b' )
如果a不存在,那么获取到的结果b也不会报错,而是undefined。
写入配置 有了上面的铺垫,写入内容也很简单。通过lowdb提供的接口,写入配置如下:
1 2 3 4 5 6 const saveConfig = (configPath: string , config: any ): void => const db = initConfig(configPath) Object .keys(config).forEach((name: string ) => { db.read().set(name, config[name]).write() }) }
我们可以用:
1 saveConfig(this .configPath, { a: { b: true } })
或者:
1 saveConfig(this .configPath, { 'a.b' : true })
上面两种写法都会生成如下配置:
1 2 3 4 5 { "a" : { "b" : true } }
可以看到明显后者更简洁点。这多亏了lowdb里由lodash提供的set方法。
至此我们已经将配置文件相关的操作实现完了。其实可以把这堆操作封装成一个类的,PicGo-Core在一开始实现的时候觉得东西不多不复杂,所以只是抽成了一个小工具来调用的。当然这个不是关键,关键在于实现了配置文件的相关操作后,你的系统和这个系统的插件都能因此受益。系统可以把跟配置文件相关的操作的API暴露给插件使用。接下去我们一步步来完善这个插件系统。
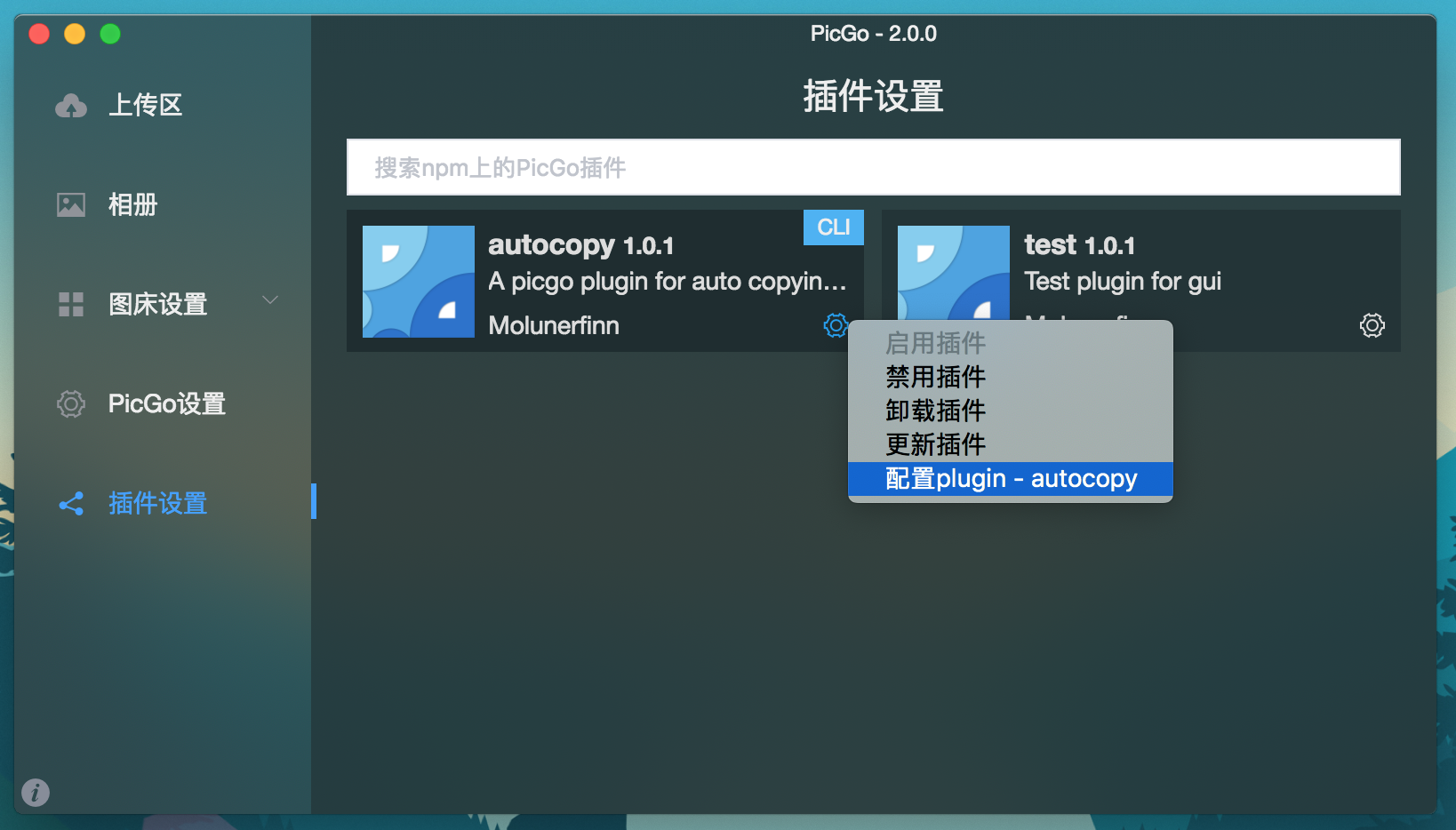
插件操作类 暂时没想好这个类要取的名字是啥,代码里我写的是pluginHandler,那么就叫它插件操作类吧。这个类主要目的就三个:
通过npm安装插件 —— install 通过npm卸载插件 —— uninstall 通过npm更新插件 —— update 用npm来分发插件,这是大多数Node.js插件系统会选择的解决方案。毕竟在没有自己的插件商店(比如VSCode)的基础上,npm就是一个天然的「插件商店」。当然发布到npm之上好处还有很多,比如可以十分方便地来对插件进行安装、更新和卸载,比如对Node.js用户来说是0成本的上手。这也是pluginHandler这个类要做的事。
pluginHandler相关的实现思路来自feflow ,特此感谢。
平时我们安装一个npm模块的时候,很简单:
不过我们是在当前项目目录的上来安装的。PicGo由于引入了配置文件,所以我们可以直接在配置文件所在的目录里进行插件的安装,这样如果你要卸载PicGo,只要把。但是每次都让用户打开PicGo的配置文件所在的路径去安装插件未免太累了。这样也不优雅。
相对的,如果我们全局安装了picgo之后,在文件系统任何一个角落里只需要通过picgo install xxx就能安装一个picgo的插件,而不需要定位到PicGo的配置文件所在的文件夹,这样用户体验会好不少。这里大家可以类比vue-cli3安装插件的步骤。
为了实现这个效果,我们需要通过代码的方式去调用npm这个命令。那么Node.js要如何通过代码去实现命令行调用呢?
这里我们可以使用cross-spawn 来实现跨平台的、通过代码来调用命令行的目的。
spawn这个方法Node.js原生也有(在child_process里),不过cross-spawn解决了一些跨平台的问题。使用上是一样的。
1 2 const spawn = require ('cross-spawn' )spawn('npm' , ['install' , '@vue/cli' , '-g' ])
可以看到,它的参数是以数组的形式传入的。
而我们要实现的插件操作,除了主要命令install、update、uninstall不一样之外,其他的参数都是一样的。所以我们抽离出一个execCommand的方法来实现它们背后的公共逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 execCommand (cmd: string , modules: string [], where: string , proxy: string = '' ): Promise <Result> { return new Promise ((resolve: any , reject: any ): void => let args = [cmd].concat(modules).concat('--color=always' ).concat('--save' ) const npm = spawn('npm' , args, { cwd: where }) let output = '' npm.stdout.on('data' , (data: string ) => { output += data }).pipe(process.stdout) npm.stderr.on('data' , (data: string ) => { output += data }).pipe(process.stderr) npm.on('close' , (code: number ) => { if (!code) { resolve({ code: 0 , data: output }) } else { reject({ code: code, data: output }) } }) }) }
关键的部分基本都已经在代码里给出了注释。当然这里还是有一些需要注意的地方。注意这句话:
1 const npm = spawn('npm' , args, { cwd: where })
里面的{cwd: where},这个where是会从外部传进来的值,表示这个npm命令会在哪个目录下执行。这个也是我们要做这个插件操作类最关键的地方——不用让用户主动打开配置文件所在目录去安装插件,在系统任何地方都可以轻松安装PicGo的插件。
接下去我们实现一下install方法,这样另外两个就可以类推了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 async install (plugins: string [], proxy: string ): Promise <void > { plugins = plugins.map((item: string ) => 'picgo-plugin-' + item) const result = await this .execCommand('install' , plugins, this .ctx.baseDir, proxy) if (!result.code) { this .ctx.log.success('插件安装成功' ) this .ctx.emit('installSuccess' , { title: '插件安装成功' , body: plugins }) } else { const err = `插件安装失败,失败码为${result.code} ,错误日志为${result.data} ` this .ctx.log.error(err) this .ctx.emit('failed' , { title: '插件安装失败' , body: err }) } }
别看代码很多,关键就一句const result = await this.execCommand('install', plugins, this.ctx.baseDir, proxy),剩下的都是日志输出而已。好了,插件也安装完了,如何加载呢?
插件加载类 上面说了,我们会将插件安装在配置文件所在目录里。值得注意的是,由于npm的特点,如果目录里有个叫做package.json的文件,那么安装插件、更新插件等操作会同时修改package.json文件。因此我们可以通过读取package.json文件来得知当前目录下有什么PicGo的插件。这也是Hexo的插件加载机制里的很重要的一环。
pluginLoader相关的实现思路来自hexo ,特此感谢。
关于插件的命名,PicGo这里有个约束(这也是很多插件系统选择的方式),必须以picgo-plugin-开头。这样才能方便插件加载类识别它们。
这里有一个小坑。如果我们配置文件所在的目录里没有package.json的话,那么执行安装插件的命令会有报错信息。但是我们不想让用户看到这个报错,于是在初始化插件加载类的时候,需要判断一下这个文件存不存在,如果不存在那么我们就要创建一个:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class PluginLoader { ctx: PicGo list: string [] constructor (ctx: PicGo ) { this .ctx = ctx this .list = [] this .init() } init (): void { const packagePath = path.join(this .ctx.baseDir, 'package.json' ) if (!fs.existsSync(packagePath)) { const pkg = { name: 'picgo-plugins' , description: 'picgo-plugins' , repository: 'https://github.com/Molunerfinn/PicGo-Core' , license: 'MIT' } fs.writeFileSync(packagePath, JSON .stringify(pkg), 'utf8' ) } } }
接下来我们要实现最关键的load方法了。我们需要如下步骤:
先通过package.json来找到所有合法的插件 通过require来加载插件 通过维护picgoPlugins配置来判断插件是否被禁用 通过执行未被禁用的插件暴露的register方法来实现插件注册 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import PicGo from '../core/PicGo' import fs from 'fs-extra' import path from 'path' import resolve from 'resolve' load (): void | boolean { const packagePath = path.join(this .ctx.baseDir, 'package.json' ) const pluginDir = path.join(this .ctx.baseDir, 'node_modules/' ) if (!fs.existsSync(pluginDir)) { return false } const json = fs.readJSONSync(packagePath) const deps = Object .keys(json.dependencies || {}) const devDeps = Object .keys(json.devDependencies || {}) const modules = deps.concat(devDeps).filter((name: string ) => { if (!/^picgo-plugin-|^@[^/]+\/picgo-plugin-/ .test(name)) return false const path = this .resolvePlugin(this .ctx, name) return fs.existsSync(path) }) for (let i in modules) { this .list.push(modules[i]) if (this .ctx.config.picgoPlugins[modules[i]] || this .ctx.config.picgoPlugins[modules[i]] === undefined ) { try { this .getPlugin(modules[i]).register() const plugin = `picgoPlugins[${modules[i]} ]` this .ctx.saveConfig( { [plugin]: true } ) } catch (e) { this .ctx.log.error(e) this .ctx.emit('notification' , { title: `Plugin ${modules[i]} Load Error` , body: e }) } } } } resolvePlugin (ctx: PicGo, name: string ): string { try { return resolve.sync(name, { basedir: ctx.baseDir }) } catch (err) { return path.join(ctx.baseDir, 'node_modules' , name) } } getPlugin (name: string ): any { const pluginDir = path.join(this .ctx.baseDir, 'node_modules/' ) return require (pluginDir + name)(this .ctx) }
load这个方法是整个插件系统加载的最关键的部分。光看上面的步骤和代码可能没办法很好理解。我们下面用一个具体的插件例子来说明。
假设我写了一个picgo-plugin-xxx的插件。我的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 module .exports = ctx => const register = () => ctx.helper.beforeTransformPlugins.register('xxx' , { handle (ctx) { console .log(ctx.output) } }) } return { register } }
我们从前文已经大概知道插件运行流程:
首先运行生命周期 当运行到某个生命周期,比如这里的beforeTransform,那么这个阶段就去获取beforeTransformPlugins这些插件 beforeTransformPlugins这些插件由ctx.helper.beforeTransformPlugins.register方法注册,并可以通过ctx.helper.beforeTransformPlugins.getList()获取拿到插件之后将调用每个beforeTransformPlugins的handle方法,并传入ctx供插件使用 注意上面的第三步,ctx.helper.beforeTransformPlugins.register这个方法是在什么时候被调用的?答案就是在本小节介绍的插件的加载阶段,pluginLoader调用了每个插件的register方法,那么在插件的register方法里,我们写了:
1 2 3 4 5 ctx.helper.beforeTransformPlugins.register('xxx' , { handle (ctx) { console .log(ctx.output) } })
也就是在这个时候,ctx.helper.beforeTransformPlugins.register这个方法被调用。
于是乎,在生命周期开始之前,整个插件以及每个生命周期的插件已经预先被注册了。所以在生命周期开始运作的时候,只需要通过getList()就可以获取注册过的插件,从而执行整个流程了。
也因此,我以前在跑Hexo生成博客的时候曾经遇到的问题就得到解释了。我以前安装过一些Hexo的插件,但是不知道为什么总是无法生效。后来发现是安装的时候没有使用--save,导致它们没被写入package.json的依赖字段。而Hexo加载插件的第一步就是从package.json里获取合法的插件列表,如果插件不在package.json里,哪怕在node_modules里有,也不会生效了。
有了插件,接下去我们讲讲如何在命令行调用和配置了。
命令行操作类 PicGo的命令行操作类主要依赖于两个库:commander.js 和Inquirer.js 。这两个也是做Node.js命令行应用很常用的库了。前者负责命令行解析、执行相关命令。后者负责提供与用户交互的命令行界面。
比如你可以输入:
这个时候由commander.js去解析这句命令,告诉我们这个时候调用的是use这个命令,参数是uploader,那么就进入Inquirer.js提供的交互式界面了:
如果你用过诸如vue-cli3或者create-react-app等类似的命令行工具一定类似的情况很熟悉。
首先我们写一个命令行操作类,用于暴露api给其他部分注册命令,此处源码可以参考Commander.ts 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import PicGo from '../core/PicGo' import program from 'commander' import inquirer from 'inquirer' import { Plugin } from '../utils/interfaces' const pkg = require ('../../package.json' )class Commander { list: { [propName: string ]: Plugin } program: typeof program inquirer: typeof inquirer private ctx: PicGo constructor (ctx: PicGo ) { this .list = {} this .program = program this .inquirer = inquirer this .ctx = ctx } } export default Commander
然后我们在PicGo-Core的核心类里将其实例化:
1 2 3 4 5 6 7 8 9 10 11 import Commander from '../lib/Commander' class PicGo extends EventEmitter { cmd: Commander constructor (configPath: string = '' ) { super () this .cmd = new Commander(this ) }
这样其他部分就可以使用ctx.cmd.program来调用commander.js以及使用ctx.cmd.inquirer来调用Inquirer.js了。
这两个库的使用,网络上有很多教程了。此处简单举个例子,我们从PicGo最基本的功能——命令行上传图片开始说起。
命令的注册 为了与之前的插件结构统一,我们把命令注册也写到handle函数里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import PicGo from '../../core/PicGo' import path from 'path' import fs from 'fs-extra' export default { handle: (ctx: PicGo): void => const cmd = ctx.cmd cmd.program .command('upload' ) .description('upload, go go go' ) .arguments('[input...]' ) .alias('u' ) .action(async (input: string []) => { const inputList = input .map((item: string ) => path.resolve(item)) .filter((item: string ) => { const exist = fs.existsSync(item) if (!exist) { ctx.log.warn(`${item} is not existed.` ) } return exist }) await ctx.upload(inputList) }) } }
这样我们如果通过某种方式把命令注册进去:
1 2 3 4 5 6 7 8 import PicGo from '../../core/PicGo' import upload from './upload' export default (ctx: PicGo): void => ctx.cmd.register('upload' , upload) }
当代码写到这里,可能大家觉得已经大功告成了。实际上还差了最后一步,我们缺少一个入口来接纳我们输入的命令。就比如现在我们写完了命令,也写完了命令的注册,然后我们要怎么在命令行里使用呢?
命令行的使用 这个时候要简单说下package.json里的两个字段bin和main。其中main字段指向的文件,是你const xxx = require('xxx')的时候拿到的东西。而bin字段指向的文件,就是你在全局安装了之后,可以在命令行里直接输入的命令。
举个例子,PicGo-Core的bin字段如下:
1 2 3 4 "bin": { "picgo": "./bin/picgo" },
那么用户如果全局安装了picgo,就可以通过picgo这个命令来使用picgo了。类似安装@vue/cli之后,可以使用vue这个命令一样。
那么我们来看看./bin/picgo做了啥。源码在这里 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #!/usr/bin/env node const path = require ('path' )const minimist = require ('minimist' )let argv = minimist(process.argv.slice(2 )) let configPath = argv.c || argv.config || '' if (configPath !== true && configPath !== '' ) { configPath = path.resolve(configPath) } else { configPath = '' } const PicGo = require ('../dist/index' )const picgo = new PicGo(configPath) picgo.registerCommands() try { picgo.cmd.program.parse(process.argv) } catch (e) { picgo.log.error(e) if (process.argv.includes('--debug' )) { Promise .reject(e) } }
关键部分就在picgo.cmd.program.parse(process.argv)这句话,这句话调用了commander.js来解析process.argv,也就是命令行里命令以及参数。
那么我们在开发阶段就可以用./bin/picgo upload这样来调用命令,而在生产环境下,也就是用户全局安装后,就可以通过picgo upload这样来调用命令了。
配置项的处理 前文提到了,配置项是插件系统里很重要的一个组成部分。不同插件系统的配置项处理不太一样。比如Hexo提供了_config.yml供用户配置,vue-cli3提供了vue.config.js供用户配置。PicGo也提供了config.json供用户配置,不过在此基础上,我想提供一个更方便的方式来让用户直接在命令行里完成配置,而不需要专门打开这个配置文件。
比如我们可以通过命令行来选择当前上传的图床是什么:
1 2 3 4 5 6 7 8 9 10 $ picgo use ? Use an uploader (Use arrow keys) smms ❯ tcyun weibo github qiniu imgur aliyun (Move up and down to reveal more choices)
这种在命令行里的交互,需要之前提到的Inquirer.js来辅助我们达到这个效果。
它的用法也很简单,传入一个prompts(可以理解为一个问题数组),然后它会将问题的结果再以对象的形式返回出来,我们通常将这个结果记为answer。
而PicGo为了简化这个过程,只需要插件提供一个config方法,这个方法只需返回一个合法的prompts问题数组,然后PicGo会自动调用Inquirer.js去执行它,并自动将结果写入配置文件里。
举个例子,PicGo内置的Imgur图床的config代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 const config = (ctx: PicGo): PluginConfig[] => { let userConfig = ctx.getConfig('picBed.imgur' ) if (!userConfig) { userConfig = {} } const config = [ { name: 'clientId' , type : 'input' , default : userConfig.clientId || '' , required: true }, { name: 'proxy' , type : 'input' , default : userConfig.proxy || '' , required: false } ] return config } export default { config }
然后我们用代码实现能够在命令行里调用它,源码传送门 :
以下代码有所精简
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import PicGo from '../../core/PicGo' import { PluginConfig } from '../../utils/interfaces' const handleConfig = async (ctx: PicGo, prompts: PluginConfig, name: string ): Promise <void > => { const answer = await ctx.cmd.inquirer.prompt(prompts) let configName = `picBed.${name} ` ctx.saveConfig({ [configName]: answer }) } export default { handle: (ctx: PicGo): void => const cmd: typeof ctx.cmd = ctx.cmd cmd.program .command('set' ) .alias('config' ) .description('configure config of picgo' ) .action(async () => { try { let prompts = [ { type : 'list' , name: 'uploader' , choices: ctx.helper.uploader.getIdList(), message: `Choose a(n) uploader` , default : ctx.config.picBed.uploader || ctx.config.picBed.current } ] let answer = await ctx.cmd.inquirer.prompt(prompts) const item = ctx.helper.uploader.get(answer.uploader) if (item.config) { await handleConfig(ctx, item.config(ctx), answer.uploader) } ctx.log.success('Configure config successfully!' ) } catch (e) { ctx.log.error(e) if (process.argv.includes('--debug' )) { Promise .reject(e) } } }) } }
上面是针对Uploader的config方法进行的配置处理,对于其他插件也是同理的,就不再赘述。这样我们就实现了能够通过命令行快速对配置文件进行配置,用户体验又是++。
插件系统发布 讲了那么多,我们都是在本地书写的插件系统,如何发布让别人能够安装使用呢?关于往npm发布模块有很多相关文章,比如参考这篇文章 。我在这里想讲的是如何发布一个既能在命令行使用,又可以通过比如const picgo = require('picgo')在Node.js项目里使用API调用的库。
CLI与API调用并存 其实这个上面的部分里也提到了。我们在发布一个npm库的时候通常是在package.json里的main字段指定这个库的入口文件。那么这样使用者就可以通过比如const picgo = require('picgo')在Node.js项目里使用。
如果我们想要让这个库安装之后能够注册一个命令,那么我们可以在bin字段里指定这个命令已经对应的入口文件。比如:
1 2 3 4 "bin": { "picgo": "./bin/picgo" },
这样我们在全局安装之后就会在系统里注册一个叫做picgo的命令了。
当然这个时候bin和main的入口文件通常是不一样的。bin的入口文件需要做好解析命令行的功能。所以通常我们会使用一些命令行解析的库例如minimist或者commander.js等等来解析命令行里的参数。
小结 至此,一个CLI插件系统的关键部分我们就基本实现了。那么我们在Electron项目里,可以在main进程里使用我们所写的插件系统,并通过这个插件暴露的API来打造应用的插件系统了。下一篇文章会详细讲述如何把CLI插件系统整合进Electron,实现GUI插件系统,并加入一些额外的机制,使得在GUI上的插件系统更加灵活而强大。
本文很多都是我在开发PicGo的时候碰到的问题、踩的坑。也许文中简单的几句话背后就是我无数次的查阅和调试。希望这篇文章能够给你的electron-vue开发带来一些启发。文中相关的代码,你都可以在PicGo 和PicGo-Core 的项目仓库里找到,欢迎star~如果本文能够给你带来帮助,那么将是我最开心的地方。如果喜欢,欢迎关注我的博客 以及本系列文章 的后续进展。
注:文中的图片除未特地说明之外均属于我个人作品,需要转载请私信
参考文献 感谢这些高质量的文章:
用Node.js开发一个Command Line Interface (CLI) Node.js编写CLI的实践 Node.js模块机制 前端插件系统设计与实现 Hexo插件机制分析 如何实现一个简单的插件扩展 使用NPM发布与维护TypeScript模块 typescript npm 包例子 通过travis-ci发布npm包 Dynamic load module in plugin from local project node_modules folder 跟着老司机玩转Node命令行 以及没来得及记录的那些好文章,感谢你们!